今天的主題是 LlamaIndex 的主要功能介紹, LlamaIndex 集成了 Chatbot 中的大部分應用,從QA、多輪對話到 Agent,大致可分為以下模組: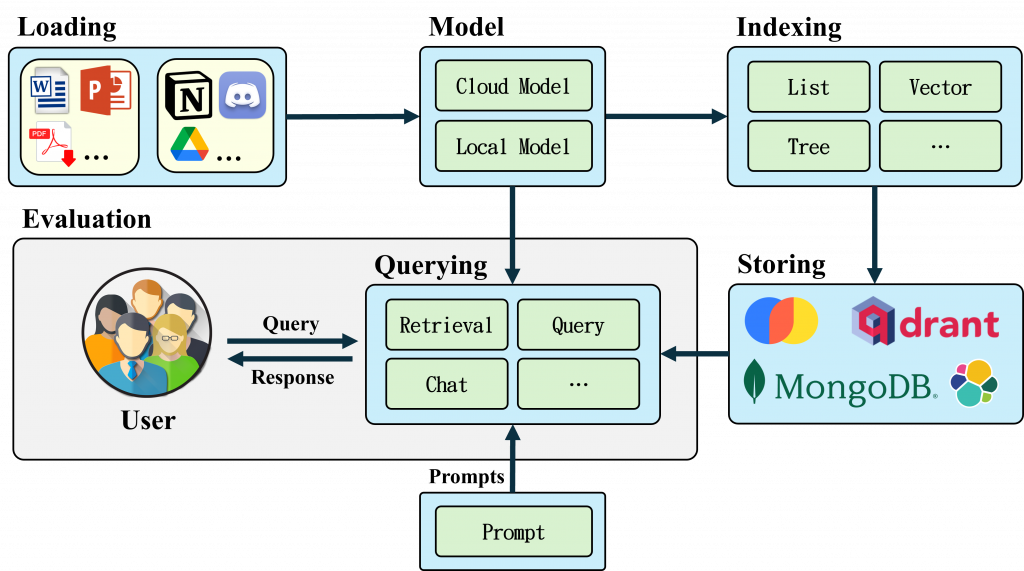
透過 Llama Hub 支援多種資料來源,如本地文件、網頁、資料庫等。
提供 LlamaParse 支援多種文件格式,並提供OCR、圖片讀取、轉換輸出格式(如Markdown, Json...)等功能。(免費額度每天1000頁)
提供異步載入管道,支援大規模資料處理。
支援元數據(Metadata)提取,增加檢索效果。
LLMs:
Embedding:
Multi Modal:
支援自定義 Prompt 模板,可用於各類型任務、問答等,包含QA、refine、text-to-sql等。
支援多種索引方式,如向量索引、關鍵詞索引等。
提供分布式索引,支援大規模資料索引。
支援元數據提取,方便使用者快速提取Summary、Keyword、Entity等資訊。
支援多種VectorDB,如ChromaDB、Qdrant、Pinecone。
支援Index/Document Stores,如MongoDB、Redis。默認情況下,這些資訊會存儲在記憶體中。
支援Chat Stores多輪對話歷史資料儲存。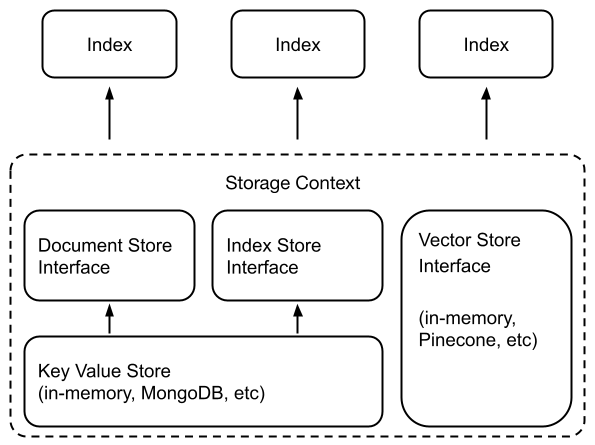
支援多種檢索方式,如BM25 Retrieval、Embedding Retrieval等。
提供檢索結果優化,如Reranker、Filter等。
提供更多進階查詢方法,如Router、SQL、Sub-Question等。
支援多種生成評估指標,如正確性、幻覺等。
支援多種檢索評估指標,如精確度、命中率等。
支援多種代理模型,如聊天機器人、問答系統等
提供可控代理,支援任務分解、結果解釋等
支援代理微調,提升代理性能
LlamaIndex 模組化了 LLMs 的整個框架,從檔案讀取到Agent、評估效果一條龍的開發流程,能透過簡短的程式碼快速更換各種模型、檢索器、儲存桶等,大幅減少了開發者的研發時間消耗。接著筆者將會針對各項功能更深入的一一介紹,有興趣的朋友歡迎一起討論。



 iThome鐵人賽
iThome鐵人賽